Dataset Archiving
Overview
The diagram below shows how Mendeley Data ingests, manages, archives and provides access based on the Open Access Information System (OAIS) model.
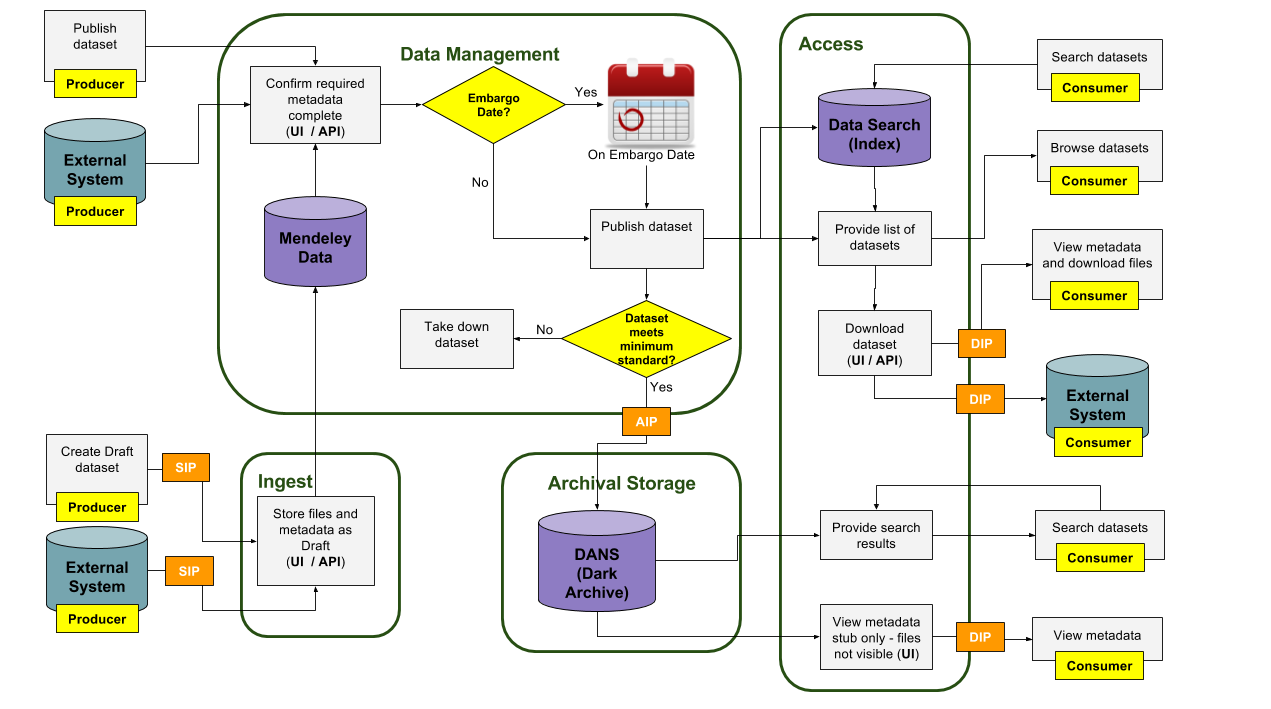
Ingest
An end user (person) can create a Draft dataset in Mendeley Data via the web-based User Interface. As soon as a draft dataset is first created, it is auto-saved, and stored safely. Alternatively, any external system can be configured to create a Draft dataset via the public API.
Examples of external systems that upload data to Mendeley Data via the public API are:
- EVISE – Elsevier's article publication workflow system
- Hivebench – Elsevier's Electronic Laboratory Notebook (ELN)[HC5]
Creating a Draft dataset involves uploading files up to a total file size limit of 10GB per dataset.
- Title
- Contributors – including Author and others referenced by email address
- Institutions – the institutions (e.g. universities) and/or units (e.g. departments/faculties) associated with this research
- Categories – sourced from Elsevier’s OmniScience taxonomy
- Description – free text description of the data
- Steps to reproduce – free text description of the steps required to reproduce the investigation
- Related links – links to any related datasets, articles, software or other entity associated with this dataset
- License – a range of copyright licenses is available to be selected
The user or external system can[HC6] also specify metadata for the dataset, this currently includes:
- Title
- Contributors – including Author and others referenced by email address
- Institutions – the institutions (e.g. universities) and/or units (e.g. departments/faculties) associated with this research
- Categories – sourced from Elsevier’s OmniScience taxonomy
- Description – free text description of the data
- Steps to reproduce – free text description of the steps required to reproduce the investigation
- Related links – links to any related datasets, articles, software or other entity associated with this dataset
- License – a range of copyright licenses is available to be selected
Data Management
Datasets can be published (via UI and API) so that they are accessible by the general public.
Before a dataset can be published, the following mandatory metadata fields must be completed:
- Title
- Contributor(s)
- Categories
- Description
- License
The dataset can be published immediately, or an embargo date can be set to make the dataset available in the future. In this case, the title of the dataset is published immediately, but the remaining metadata and files are not made public until the embargo date.
At this point the dataset receives a new Digital Object Identifier (DOI) from DataCite.
[J(7)] Once a dataset is published, a Mendeley Data reviewer will review the dataset to ensure that it complies with the following standards:[HC8]
Datasets must be:
- scientific in nature
- research data – rather than the research article, which may have resulted from the research
Datasets must not:
- have already been published, and therefore not already have a DOI
- contain executable files or archives that are not accompanied by indiidually detailed file descriptions.
- contain copyrighted content (audio, video, image, etc)
- contain sensitive information (for example, but not limited to: exact names, dates of birth etc.). Per 4.4.7 of our Terms, authors must "have obtained all necessary consents”; and “data [must be] suitably anonymized wherever appropriate". This means that data with disclosure risk must not be shared, except where consent has been given, or should be anonymised.
These requirements are indicated to authors in our FAQs and/or in Terms.
In addition to the review process, we provide a “Report this dataset” facility on every dataset page. Datasets alerted to us using this mechanism will be reviewed immediately.
In these cases, the dataset will be taken down and the author informed.
Archival Storage
Once a dataset has been confirmed as being valid based the on the criteria listed above, it is then archived in the Data Archiving and Network Services (DANS) long term repository [HC10].
Mendeley have contracted with DANS to ensure thatall published and valid datasets are archived in perpetuity If in the future, the Mendeley Data site ceases to exist, all archived datasets will still be available in DANS.
DANS guarantees long-term bit-level preservation of all file formats. In addition, DANS uses a list of preferred data formats for which it guarantees long-term usability.
While datasets are discoverable in DANS, only the metadata can be seen. The files themselves are currently only viewable from Mendeley Data.
Note that embargoed datasets won’t be archived in DANS until their embargo date.
Access
Datasets can be viewed and downloaded from the Mendeley Data website by end users. External systems are also able to query and download any published and valid dataset via the Mendeley Data public API.
Mendeley Data also provides a search capability powered by Elsevier’s DataSearch platform. This provides full text search of metadata and files as well as the ability to filter search results by subject area categories.
As all datasets have a permanent DOI, they can also be reliably referenced from published articles or other related datasets.
IT resource management, crisis management
Research data and user data held by Mendeley Data is stored securely on Amazon Simple Storage Service (S3), part of Amazon Web Services (AWS).
Amazon S3 ensures against data loss by “quickly detecting and repairing any lost redundancy.” Additionally, by using Amazon S3 the repository benefits from best in class protection against file storage deterioration: Amazon S3 storage is designed to provide 99.999999999% durability of objects over a given year.
In addition, datasets which pass review are archived with DANS, as described above, which further ensures they are backed up.